day 01
云计算的概念:云计算是一种运营模式,按量计费的模式,它的底层主要就是通过虚拟化的技术去实现的。
为什么要使用云计算:
1、小公司:弹性伸缩、扩展,节约成本;
2、大公司:云计算厂商,都有一个内存压缩机制
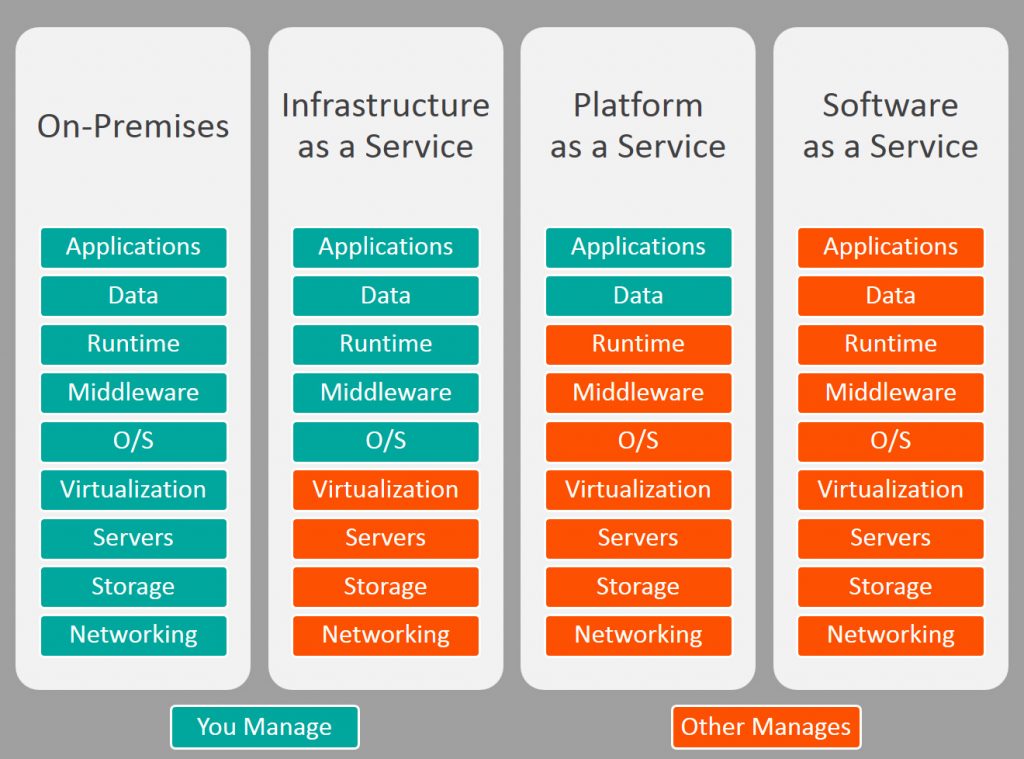
云计算的几种服务模式:
1、IAAS:基础设施即服务;底层使用的虚拟化技术,大部分云厂商提供的云主机底层基本上使用的都是KVM虚拟化技术,KVM的管理平台openstack(开源平台);
2、PAAS:平台即服务,docker容器+K8S容器编排管理技术;
3、SAAS:软件即服务;需要运维+开发,
虚拟化:通过模拟计算机物理硬件,来实现同一台物理机上运行多个虚拟出的多个不同的操作系统的技术。
一般物理服务器都会做bond(俗称:端口聚合)
主流的虚拟化技术:kvm(性能及兼容性居中均衡)、qemu(发展是 最早的、性能最慢的、但可以模拟所有的硬件)、xen(性能最好,但一般的内核使用不了,使用专用定制版的内核,即兼容性差)、vmware ESXI(商业软件)
KVM: Kernel-based Virtual Machine(基于内核的虚拟机) 开源
优化阿里云更新源的额地址:
https://developer.aliyun.com/mirror/
KVM虚拟化管理软件的安装
yum install libvirt virt-install qemu-kvm -y
libvirt作用:虚拟机的管理软件,管理虚拟机的生命周期,它是一款通用的虚拟机管理软件,它还能管理xen、qemu、lxc等
virt中的virt-install、virt-clone 作用:虚拟机的安装工具和克隆工具
qemu-kvm qemu-imq(qcow2,raw)作用:管理虚拟机的虚拟磁盘
systemctl start libvirtd.service 用来开启虚拟机管理软件
systemctl status libvirtd.service
创建一台kvm虚拟机的命令:
virt-install –virt-type kvm –os-type=linux –os-variant rhel7 –name centos7 –memory 1024 –vcpus 1 –disk /opt/centos7.raw,format=raw,size=10 –cdrom /opt/CentOS-7-x86_64-Minimal-1708.iso –network network=default –graphics vnc,listen=0.0.0.0 –noautoconsole
解释:
–virt-type:虚拟化类型,默认使用的虚拟化类型是qemu
–os-type:操作系统的类型
–os-variant:操作系统版本
选择虚拟化类型及操作系统版本目的是使创建的虚拟机按照特定的版本进行优化,提升虚拟机的性能
–name:指定虚拟机的名字,注意:每个虚拟机的名字不能重复
–graphics:图形图像输出的格式类型
虚拟机管理软件libvirt主要是通过virsh命令来进行日常管理与配置的
查看当前虚拟机列表:virsh list只显示当前运行的状态的虚拟机和挂起的虚拟机,如果想显示所有的虚拟机可以加–all参数,即:virsh list –all
开机:virsh start 虚拟机名
关机: virsh shutdown 虚拟机名 (只有进了系统,才能使用)
拔电源关机: virsh destroy 虚拟机名 (注意:生产环境不到万不得已,千万不要轻易拔电源,容易造成数据的丢失)
重启: virsh reboot 虚拟机名
备份KVM虚拟机,要备份两个文件:1、磁盘文件(如:centos7.raw)2、配置文件(如:centos7.xml),备份配置文件的命令为:virsh dumpxml centos7 >>centos7.xml
删除虚拟机的命令:virsh undefine 虚拟机名字,推荐虚拟机先destroy,然后再undefine,这个命令只是删除虚拟机的配置文件,磁盘文件还是存在的。
恢复虚拟机的命令:virsh define 虚拟机配置文件的路径
一种恶搞故障:当某台虚拟机在运行状态下,我们执行:virsh undefine 虚拟机的名字,然后再关闭此虚拟机,就会发生关一台少一台的故障。每当我们启动一台虚拟机都会在后台有一个进程ps -ef |grep qemu
KVM默认的配置文件路径在:/etc/libvirt/qemu/下
要修改配置文件的方法:virsh edit 虚拟机名,通过此方法可以进行语法检测
给虚拟机改名字:virsh domrename 原来的名字 新的名字 (注意:更改名字的时候需要将该虚拟主机进行关机)
虚拟机挂起:virsh suspend 虚拟机的名字
恢复虚拟机:virsh resume 虚拟机的名字
查看某台虚拟机对应的VNC所对应的端口号:virsh vncdisplay 虚拟机名 (注意:vnc有两种端口号,一种是长端口号,一种是短端口号)
设置kvm虚拟机开机自起:virsh autostart 虚拟机名字 ,这样虚拟机就会随着宿主机的开机启动自动启动运行,这在宿主机宕机恢复的时候比较有用。
查看当前宿主机上的所有宿主机哪些是开机自启的:可以查看 /etc/libvirt/qemu/autostart/下有一个xml文件,这个文件是阮链接文件
取消kvm虚拟机开机自启的命令:第一种方法,在/etc/libvirt/qemu/autostart/删除要关闭的虚拟机对应的xml文件即可;第二种方法,通过命令:virsh autostart –disable 虚拟机名字
设置kvm虚拟机console登录:
1、首先通过以下命令来修改KVM虚拟机的内核参数:
grubby –update-kernel=ALL –args=”console=ttyS0,115200n8”
reboot
当然也可以通过vi来修改内核参数 /boot/grub2/grub.cfg
2、然后执行virsh console 虚拟机名字
如果想从登录的consolo虚拟机回到宿主机,可以使用快捷键ctrl+]
kvm的磁盘格式:
1、raw:裸格式,占用空间比较大,不支持快照功能,性能较好,不方便传输
2、qcow和qcow2(qcow2的性能比qcow好很多,所以现在基本上都用qcow2格式),cow(copy on wirte写时复制),占用的空间小,支持快照,性能比raw差一点
虚拟磁盘的管理命令:
查看虚拟磁盘的信息:qemu-img info 虚拟机的磁盘文件 例如:qemu-img info centos7.qcow2
创建虚拟磁盘的命令:qemu-img create -f qcow2 /opt/centos.qcow2 10G
-f 是指定创建硬盘的格式
不加参数 -f 默认创建的磁盘格式是raw
调整虚拟磁盘的容量:qemu-img resize /opt/centos7.qcow2 +10G 此命令是将虚拟磁盘的容量在原有容量的基础上再扩容10G
qemu-img resize /opt/centos7.qcow2 30G 此命令是直接将虚拟磁盘的容量扩容到30G
转换磁盘格式:qemu-img convert -f raw -O qcow2 centos7.raw centos7.qcow2
qemu-img convert -f 源文件的格式 -O 转后的文件格式 源磁盘文件的文件名 转后的目标磁盘文件的文件名
kvm虚拟机创建快照: virsh snapshot-create centos7 这样创建的快照名是以时间戳的格式命名
查看某个虚拟机有多少快照:virsh snapshot-list centos7
删除某个虚拟机的某个快照:virsh snapshot-delete centos7 –snapshotname 1122334455
创建kvm虚拟机快照并给快照进行自定义命名:virsh snapshot-create-as centos7 –name yuanshi
给某台虚拟机恢复快照:virsh snapshot-revert centos7 –snapshotname yuanshi
kvm虚拟机克隆分为两种:1、完整克隆;2、链接克隆
完整克隆又分为两种:1、自动克隆(通过工具); 2、手动克隆
virt-clone这个工具受virt-install工具的依赖,所以这个工具是已经安装的
完整克隆的命令:virt-clone –auto-clone -o centos7 -n new_centos7 切记,在进行虚拟机克隆的时候,虚拟机的运行状态必须是关机或挂起状态,注意:自动克隆出来的虚拟机是自带压缩,不带快照的
手动克隆:注意,千万不要克隆带快照的虚拟机,因为克隆后,虚拟机里的快照起不来。
第一步,拷贝虚拟机磁盘文件:cp new_centos7.qcow2 new1_centos7.qcow2
第二步,导出源虚拟机的配置文件 virsh dumpxml new_centos7 > new1_centos7.xml
第三步,编辑导出虚拟机的配置文件,vim new1_centos7.xml,注意:1、修改虚拟机的名字;
第四步,导入克隆编辑后的虚拟机配置文件new1_centos7.xml,即:virsh define new1_centos7.xml
链接克隆:
注意,官方是没有链接克隆的工具,它只有完整克隆
第一步,qemu-img create -f qcow2 -b centos7.qcow2 new2_centos7.qcow2
参数-b指的是我要基于那块磁盘文件创建一个引用磁盘
第二步,导出源虚拟机的配置文件 virsh dumpxml centos7 > new2_centos7.xml
第三步,编辑导出虚拟机的配置文件,vim new2_centos7.xml,注意:1、修改虚拟机的名字;
第四步,导入克隆编辑后的虚拟机配置文件new2_centos7.xml,即:virsh define new2_centos7.xml
day 02
默认的虚拟机网络是NAT模式
kvm也可以配置端口映射,方法是:1、iptables -t nat -L -n 查看的是NAT表 2、添加规则做端口映射
kvm虚拟机默认是没有开启桥接模式的,我们需要通过命令开启桥接模式,命令为:virsh iface-bridge eth0 br0 ,注意kvm开启桥接模式之前,其宿主机一定不能是DHCP模式,开启kvm虚拟机桥接模式,会修改网卡的配置文件
注意:kvm虚拟机在开启桥接模式的时候,会报错,主要原因是:发现 eth0和br0都有ip

1 | 解决方法:执行以下命令 |
开启桥接模式的虚拟机的命令:virt-install –virt-type kvm –os-type=linux –os-variant rhel7 –name lijianbo –memory 1024 – vcpus 1 –disk /opt/lijianbo.qcow2 –boot hd –network bridge=br0 –graphics vnc,listen=0.0.0.0 –noautoconsole
手动更改已创建的KVM虚拟机的网络模式为桥接模式,可以修改该虚拟机的配置文件,virsh edit 该虚拟机名 ,修改里面的内容,如:
1 | <interface type='bridge'> |
注意,这个手动修改,必须在宿主机上重启虚拟机才生效
将已创建的桥接网卡取消掉的命令为:
virsh iface-unbridge br0
热添加技术:
1、给kvm虚拟机热添加一块虚拟磁盘的操作步骤:
1 | qemu-img create -f qcow2 lijianbo_add.qcow2 50G # 首先先创建一块虚拟磁盘,格式为qcow2,容量为:50G |
格式化后对磁盘进行挂载:
1 | mount /dev/vdb /mnt |
2、如果想在已热添加虚拟磁盘的kvm虚拟机剥离添加的磁盘,可以使用以下的内容:
1 | virsh detach-disk lijianbo vdb |
3、如果热添加的磁盘容量不够,为热添加的磁盘进行扩容的步骤:扩容一定要规范操作,注意,扩容的时候并不会丢失原来的数据
1 | 1、umount /mnt # 先卸载挂载的磁盘,注意此操作是在虚拟机执行的 |
4、热添加网卡:
1 | virsh attach-interface lijianbo bridge br0 --model virtio --config # kvm虚拟机热添加一块虚拟网卡模式为virtio,并将网卡信息添加到配置文件中 |
5、热添加内存:
注意,虚拟机热添加内存是有前提条件的:即在创建虚拟机的时候指定一个参数maxmemory设置它弹性最大能扩展的内存容量是多少,例如:
1 | virt-install --virt-type kvm --os-type=linux --os-variant rhel7 --name lijianbo1 --memory 512,maxmemory=2048 --vcpus 1 --disk path=/opt/lijianbo1.qcow2 --boot hd --network bridge=br0 --graphics vnc,listen=0.0.0.0 --noautoconsole |
注意:参数–config,加上是永久生效,不加,就是临时生效。
6、热添加cpu核数:
注意,虚拟机热添加CPU核数跟虚拟机热添加内存的情况是相同的,都是有前提条件的:即在创建虚拟机的时候指定一个参数maxvcpus设置它弹性最大能扩展的cpu核数是多少,例如:
1 | virt-install --virt-type kvm --os-type=linux --os-variant rhel7 --name lijianbo2 --memory 512,maxmemory=2048 --vcpus 1,maxvcpus=10 --disk path=/opt/lijianbo1.qcow2 --boot hd --network bridge=br0 --graphics vnc,listen=0.0.0.0 --noautoconsole |
注意:参数–config,加上是永久生效,不加,就是临时生效。
KVM虚拟机迁移:
冷迁移KVM虚拟机:配置文件、磁盘文件
热迁移KVM虚拟机:配置文件、NFS共享
| 主机 | IP地址 | 软件 | 配置要求 |
|---|---|---|---|
| kvm01 | 10.0.0.11 | kvm管理软件+nfs客户端 | 2G,开启虚拟化 |
| kvm02 | 10.0.0.12 | kvm管理软件+nfs客户端 | 2G,开启虚拟化 |
| nfs01 | 10.0.0.31 | nfs服务端 | 1G |
热迁移的准备工作:
1、准备两台kvm宿主机,配置桥接网络,nfs客户端
2、安装nfs服务端
3、kvm宿主机挂载nfs服务端,挂载点一定要是同一个目录
4、启动一台新的虚拟机,该虚拟机磁盘文件存储在共享存储上
5、演示命令行热迁移
6、安装图形界面virt-manager
第一步操作:安装nfs服务端及客户端的命令:yum install nfs-utils -y
第二步操作:nfs服务端配置启动,配置:vim /etc/exports修改里面的内容:
/opt 10.0.0.0/24(rw,sync,no_root_squash,no_all_squash)
共享目录 允许10网段访问(可以使用的权限,sync,我们这里不做uid映射及gid映射
然后执行:systemctl restart rpcbind
重新执行nfs服务:systemctl restart nfs
第三步操作:在两台宿主机上执行挂载远端nfs共享目录的命令:
mount -t nfs 10.0.0.31:/opt /opt # 远端nfs的10.0.0.31的/opt目录挂载到本地的/opt目录
通过df -h可以检查是否挂载上远端的nfs共享目录
第四步操作:启动一台虚拟机:
1 | virt-install --virt-type kvm --os-type=linux --os-variant rhel7 --name migrate --memory 1024,maxmemory=2048 --vcpus 1,maxvcpus=10 --disk /opt/centos7.qcow2,format=raw,size=10 --cdrom /opt/CentOS-7-x86_64-Minimal-1708.iso --network network=default --graphics vnc,listen=0.0.0.0 --noautoconsole |
第五步操作:进行热迁移:
注意:在做热迁移的时候两台宿主机的主机名不能相同,同时两台宿主机之间要做host解析
1 | virsh migrate --live --verbose migrate qemu+ssh://10.0.0.12/system --unsafe |
在kvm上虚拟机上安装图形界面、vnc服务端和virt-manager:
yum groups install “GNOME Desktop” -y
yum install tigevnc-server.x86_64 -y
yum install virt-manager -y
服务端启动vnc服务的命令: vncserver : 10
安装虚拟机管理软件的命令:yum install virt-manager.noarch -y
带计费功能的kvm管理平台,openstack能实现的功能:
1、查看每一个宿主机有多少台虚拟机;
2、查看每一个宿主机还剩多少资源;
3、查看每一台宿主机,每一个虚拟机的IP地址是什么
获得信息,宿主机总配置、剩余的总配置、虚拟机的信息,配置信息,IP地址,操作系统等信息
openstack是由python开发的开源的云平台,由 Rackspace和NASA共同开发。openstack实际就是一个项目,它里面的基础架构:计算,网路,存储,有一个dashboard的由django写的web界面,openstack各个组件都是通过restapi消息队列进行通信,openstack应用很广:IBM,京东,红帽、用友等各大厂商都加入openstack阵营。openstack版本是按照英文字母的顺序来排的。
1、horizon:提供一个web界面的dashboard用于管理openstack的各种服务,基于web的管理接口,通过图形界面实现创建用户、管理网络、启动实例等操作
2、glance:镜像管理,提供镜像的注册和存储管理
3、swift:对象存储,例如新浪的图像服务做的就是对象存储
4、nova:计算节点,收集各个虚拟机的硬件分配资源等信息。
5、keystone:是做验证的,做认证管理,各个组件之间通过API进行通信,他们之间的通信是需要做验证的,就需要keystone的功能,soa(服务化治理)就需要各个服务之间的通信就需要进行keystone的验证机制。soa就是对服务进行解耦合,京东用的就是soa dubbo分布式服务框架
6、neutron:实现虚拟机的网络资源管理
7、Cinder:快存储,提供存储资源池
8、ceilometer:提供监控和数据采集、计量服务(公用云用的比较多)
9、heat:自动化部署组件
10、trove:提供数据库应用服务,容易出现IO瓶颈
注意:openstack依赖于主机名,一旦主机名更改,它会把你的主机当做新加入的节点,把上面的虚拟机都给删了。
本次实验:
准备两台虚拟机,一台虚拟机做为openstack的控制节点,一台虚拟机作为openstack的计算节点(专门用来安装虚拟机)。
1、首先需要确定iptables防火墙是关闭的,命令:chkconfig iptables off;
2、检测selinux是关闭的,操作命令:vim /etc/sysconfig/selinux 将里面的SELINUX=enforcing改为disabled;
3、重启reboot;
4、内核参数调整:
vim /etc/sysctl.conf
net.ipv4.ip_forward=1 # 开启IP转发
net.ipv4.conf.all.rp_filter=0 # 开启反向路径过滤
net.ipv4.conf.default.rp_filter=0
执行sysctl -p,让配置生效
5、为两个节点添加hosts文件解析,并修改主机名
6、为两个节点添加yum源及更新操作,执行:yum makecache && yum update -y
7、时间服务器配置:
所有节点安装chrony工具,yum install chrony -y
控制节点修改配置:
vim /etc/chrony.conf
server ntp.staging.kycloud.lan iburst
allow 管理网络网段(ip/24),例如:allow 192.168.33.0/24
其余节点修改配置:
vim /etc/chrony.conf
server 控制节点IP iburst,例如:server 192.168.33.128 iburst
所有节点开启chronyd服务并设置开机启动:
systemctl enable chronyd.service
systemctl start chronyd.servicev
时区不是Asia/Shanghai需要修改时区:
timedatectl set-local-rtc 1 # 将硬件时钟调整为与本地时钟一致,0为设置UTC时间
timedatectl set-timezone Asia/Shanghai # 设置系统时区为上海
如果不考虑各个发行版的差异,修改时间时区比想象的要简单:
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
然后让每台机器同步时间就执行:
chronyc sources
8、安装软件包,防止软件自动更新
yum install yum-plugin-priorities -y # 防止自动更新
9、下载安装openstack软件仓库(queens版本)
1 | yum install centos-release-openstack-queens -y |
更新所有节点软件包
1 | yum upgrade |
9、安装openstack客户端工具:
yum install python-openstackclient -y
day03 docker容器技术
容器:容器就是在隔离的环境里运行的一个进程,如果进程停止,容器就会销毁。隔离的环境拥有自己的系统文件、ip地址,主机名等
容器和传统虚拟化的区别:
1、kvm虚拟化需要硬件的支持,需要模拟硬件,可以运行不同的操作系统,启动时间分钟级(有开机的启动流程),注意:传统linux kvm虚拟机开机流程:先bios开机自检,根据bios的设置的启动项开始启动,读取硬盘分区表信息及内核加载路径—–以前用的GRUB引导使用的是mbr分区(最大识别的硬盘容量为2T),现在使用的是UEFI引导使用的是gpt分区(就没有硬盘容量的限制),每个引导都支持多系统,加载内核,启动第一个进程/sbin/init systemd,系统初始化完成,开始运行服务;
2、容器启动流程:公用宿主机内核,第一个进程直接启动服务,轻量级,损耗资源少,启动快(秒级),性能高,但只能运行在linux上面
容器技术的发展过程:
1、chroot(change root):改变根目录,新建一个子系统(拥有自己完整的系统文件)比如在centos7的系统里拷入ubuntu的系统文件,通过chroot就可以将根目录切换到ubuntu下,执行ubuntu里的命令,但内核公用的还是centos7的内核,
在救援模式下,还可通过chroot修改系统的密码, chroot /mnt/sysimage
小知识点:linux不解压看一个压缩文件里面有哪些文件的命令,tar tf 压缩文件,例如:tar tf rootfs.tar.xz
2、lxc:linux容器(lxc),linux container(namespaces命名空间 隔离环境及cgroups资源限制),lxc已经过时了,现在基本上已经废弃了。
容器技术:
lxc: 它的进程比较多,第一个进程/sbin/init 然后再启动服务
docker: 精简,直接启动服务
rkt: rancher公司开发的产物
3、docker:docker继承了lxc的优点,进程虚拟化技术,通过namespace及cgroup(cgroup的作用就是限制进程使用多少内存、cpu、硬盘等资源)来提供容器的资源隔离与资源限制的安全保障等特性。
docker初期使用的是lxc容器引擎,但后期就是用自主开发的libcontainer容器引擎
docker-ce的安装:
1、御载旧版本docker(如果有旧版本)
在安装新版的docker之前,如果有安装旧版的docker,需要先删除旧版,步骤如下:
首先搜索已经安装的docker 安装包
1 | yum list installed|grep docker |

从说可以看出有三个docker安装包,删除这三个安装包:
1 | yum –y remove containerd.io.x86_64 |
2、设置yum镜像源为阿里镜像源,加快安装速度
1 | yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo |
docker的主要组成部分:
docker是传统意义上的CS架构,即分为docker client和docker server
docker主要组件有:镜像、容器、仓库、网络、存储
注意:启动容器必须通过一个镜像,仓库中只存储镜像,镜像可以理解为是系统文件打包之后的文件
容器—镜像—仓库
docker使用的宗旨目标是“Build(构建)、Ship(传输)and Run any App,Anywhere(处处运行)”的思路部署服务,基本上是一次构建,处处运行
配置docker国内镜像源,即给docker镜像加速:
vi /etc/docker/daemon.json
{
“registry-mirrors”:[“https://registry.docker-cn.com"]
}
测试:启动一个docker容器,并运行nignx服务
docker run -d -p 80:80 nginx
参数解释:run(创建并运行一个容器)
-d 创建的容器在后台运行
-p 端口映射,前面的是宿主机的端口,后面的是容器的端口
nginx 即docker镜像的名字
docker镜像管理
1、搜索镜像的命令:docker search 镜像名
选镜像的建议:1、优先考虑官方;2、stars星级数量高的
docker官方镜像仓库地址:hub.docker.com
2、获取镜像的命令:docker pull(下载) 镜像名:版本号 docker push(上传) 镜像名
镜像加速器:阿里云加速器,daocloud加速器,中科大加速器,docker中国官方镜像加速器(https://registry.docker-cn.com)
例如:docker pull busybox:1.29
官方pull docker pull centos:7.6 注意:没有指定版本,默认会下载最新版的镜像
私有仓库pull docker pull 私有仓库的网站地址/用户名/镜像名:版本号 例如:docker pull hub.docker.com/lijianbo/busybox:1.29
3、查看镜像列表的命令:docker images 或者 docker image ls
4、删除镜像的命令:docker rmi 镜像名:版本号 例如:docker image rm centos:latest
5、导出镜像的命令:docker save 镜像名:版本号 导出后的文件名 例如:docker image save centos >(或者-o) docker-centos.tar.gz
6、导入镜像的命令:docker load 需要导入的镜像文件 例如:docker image load -i docker-centos.tar.gz
docker的容器管理
1、docker run -d -p 80:80 nginx:latest
参数解释:run(创建并运行一个容器) docker run = docker create + docker start
-d 创建的容器在后台运行
-p 端口映射,前面的是宿主机的端口,后面的是容器的端口
nginx 即docker镜像的名字
-v 源地址(宿主机的目录):目标地址(容器上的目录)
小知识点:在linux系统中,我们也可以通过命令:hostname -I来查看主机的IP地址
2、docker run -it –name centos_new centos:6.9 /bin/bash
参数解释:-it 分配交互式的终端 -i是interactive的缩写 -t是tty的缩写
–name 指定容器的名字
/bin/bash 覆盖容器的初始命令
3、docker container ls -a 或者 docker container ls –all 查看所有容器,不加-a只显示运行状态下的容器
4、停止容器:docker stop 容器ID或者名字
将停止的容器再启动起来:docker start 容器的ID或者名字
5、杀死容器:docker kill 容器ID或者 容器名
6、查看容器列表:docker ps (-a -l -q) -l 显示最后一个容器,-q 静默输出,只显示容器的ID
7、 进入正在运行的容器:docker exec(会分配一个新的终端tty,目的是调试、排错)
1
2
3
docker exec -it 容器ID或容器名字 /bin/bash -----------------推荐使用
docker attach(使用同一个终端) 容器的ID或名字,即多个用户进入同一个容器使用的是同一个终端,即一个用户操作,输出的结果会发布到所有进入容器的终端上面,attach进入容器后退出的操作是:先按ctrl + p,松开后再按ctrl + q ---------------多人演示可以使用它
nsenter (安装yum install -y util-linux) -------------------已弃用
8、删除容器:docker rm 容器的ID或者容器名
1
2
3
4
5
它支持批量删除:docker rm 容器1的ID 容器2的ID ......
当然也可以通过查看容器ID批量删除:docker rm `docker ps -a -q`
强制删除容器的命令:docker rm -f 容器的ID或者容器名
docker容器的网络访问
查看ping这个命令的包属于谁啊,可以通过命令:yum provides ping来进行查询
注意:每次我们启动docker服务的时候,它都会自动把内核转发参数设置为1,可以通过命令:systemctl -a|grep ipv4|grep forward
如果手动调整为0,即sysctl net.ipv4.ip_forward=0,即停止转发
我们也可以通过iptables -t nat -L -n规则来进行分析
查看容器的网关的命令:route -n
docker端口映射:指定映射(docker会自动添加一条iptables规则来实现端口映射)
端口映射的几种书写格式:
-p 宿主机指定的端口:容器指定的端口
-p 宿主机网卡某个IP地址:指定的端口:容器指定的端口 例如:多个容器都想使用80端口
-p 宿主机指定的IP地址::容器指定的端口 即:将容器指定的端口映射到宿主机指定IP下的随机端口
-p 宿主机指定的端口:容器指定的端口/udp 默认端口映射使用的都是tcp协议,这里我们指定映射的端口使用的协议为udp协议
-p 81:80 -p 443:443 可以指定映射的多个端口
随机端口映射:docker run -P (使用的随机端口)
端口映射的原理就是通过iptables来实现的
docker数据卷管理
例如:docker run -d -p 80:80 -v /opt/lijianbo:/usr/share/nginx/html nginx:latest
1、目录挂载
-v 是将容器内指定的目录挂载到本地指定的目录
2、数据卷挂载
docker volume ls 用来查看有哪些卷
docker run -d -p 80:80 -v lijianbo:/usr/share/nginx/html nginx:latest 注意卷不存在会自动创建,如果卷是空的,它会把容器内的文件复制出来到卷中,如果卷里有东西了,就会把卷里的文件反挂回容器
注意:docker volume inspect lijianbo 用来看卷lijianbo的详细情况
练习:
基于nginx启动一个容器,监听80和81端口,访问80,出现nginx默认欢迎首页,访问81,出现指定页面。
提示:1、nginx默认的配置文件位置为:/etc/nginx/nginx.conf发现他包含:include /etc/nginx/conf.d/*.conf
2、cat /etc/nginx/conf.d/default.conf ,去掉注释和空行的命令:grep -Ev ‘^$|#’ /etc/nginx/conf.d/default.conf得到server的配 置文件,如:
server {
listen 80;
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
}
手动将容器保存为镜像:
制作自己的docker镜像的步骤:
1、启动一个基础容器;
例如:docker run -it centos:6.9
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
yum install nginx
2、把容器提交为镜像;
例如:docker container commit 容器ID或者容器名 (例如:7839718e89ee) 准备生成的镜像名:镜像的版本号(例如:lijianbo : v1)
docker container commit 7839718e89ee lijianbo:v1
3、测试镜像的功能是否正常 ;
docker run -d -it -p 80:80 lijianbo:v1 nginx -g ‘daemon off;’ 注:nginx -g ‘daemon off;’ 是nginx的启动命令
2、制作一个多服务的镜像:
1、启动一个基础容器
docker run -it lijianbo:v1 /bin/bash
mkdir /code
yum install php-fpm -y
vim /etc/nginx/conf.d/kod.conf
server {
listen 80;
server_name localhost;
location / {
root /code;
index index.php index.html index.htm;
}
location ~ \.php$ {
root /code;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /code$fastcgi_script_name;
include fastcgi_params;
}
}
nginx -t 检查语法错误
service nginx start
service php-fpm start
day04 dockerfile 自动构建docker镜像
dockerfile 类似于一个剧本文件,dockerfile还支持容器的定制化,以及支持自定义容器的初始命令
dockerfile的主要组成部分:
1、基础镜像信息:例如:FROM centos:6.9 注意:指定基础镜像使用的是FROM命令
2、制作镜像操作指令:例如:RUN yum install openssh-server -y 注意:后面每一个编排命令都可以使用RUN来表示
3、容器启动时执行的初始命令:例如:CMD[“/bin/bash”] 注意:CMD是指定容器启动时执行的初始命令
注意:每一个项目只能有一个dockerfile文件,例如:创建nginx镜像文件,就只能有一个dockerfile文件,并且文件名只能叫dockerfile,
使用dcokerfile构建镜像步骤:
1、手动制作一次镜像;
2、根据历史命令编写dockerfile文件
创建nginx的docker镜像的dockerfile文件格式为:
基础镜像信息:FROM centos:6.9
制作进行操作指令:RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
RUN yum install nginx unzip -y
容器启动时执行的命令:CMD [“nginx”,”-g”,”daemon off; “]
3、使用dockerfile构建镜像
然后基于上面的dockerfile文件制作镜像:docker image build -t(创建镜像的名字) centos_nginx:v1 /opt/dockerfile/nginx(dockerfile所在的目录)
docker build –network=host -t centos_nginx.:v1 –network=host 参数使用宿主机网络
4、测试镜像
–WORKDIR
制作一个带服务的dockerfile文件:
FROM centos:6.9
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
RUN yum install nginx unzip -y
WORKDIR /usr/share/nginx/html WORKDIR 用于创建的临时容器切换当前工作目录,类似于: cd /usr/share/nginx/html
RUN curl -o lijianbo.zip http://10.0.0.2/file/lijianbo.zip
RUN unzip lijianbo.zip
CMD [“nginx”,”-g”,”daemon off;”]
–ADD
在制作dockerfile文件时通过ADD将宿主机上指定的目录文件添加到临时容器指定的目录
FROM centos:6.9
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
RUN yum install nginx unzip -y
WORKDIR /usr/share/nginx/html WORKDIR 用于创建的临时容器切换当前工作目录,类似于: cd /usr/share/nginx/html
ADD lijianbo . ADD 将宿主机指定的目录放到临时容器的当前工作目录(如果给的是tar包会自动解压)
CMD [“nginx”,”-g”,”daemon off;”]
–MAINTAINER 告诉别人,谁负责维护他 (指定维护者信息,是个可选项,可有可无)
–LABLE 给制作的镜像添加描述信息,标签(是个可选项,可有可无)
–VOLUME(数据卷持久化)
在制作dockerfile文件时通过volume将指定的目录进行持久化
FROM centos:6.9
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
RUN yum install nginx unzip -y
ADD lijianbo /usr/share/nginx/html ADD 将宿主机指定的目录放到临时容器的当前工作目录
VOLUME /usr/share/nginx/html VOLUME将指定的目录进行持久化
CMD [“nginx”,”-g”,”daemon off;”]
只有使用dockerfile生成的镜像运行的容器,数据卷才可以生效,查询某个容器挂载的数据卷的详细信息可以通过如下命令:docker container inspect 容器名或者容器ID|grep -i volume
docker run -d -p 88:80 –volumes-from nginx_lijianbo(指定的容器) lijianbo:v3 –volumes-from指的是新建的容器与指定的容器挂载相同的数据卷
–EXPOSE(指定对外开放的端口与随机端口的映射关系),使用docker run -P,如果在dockerfile文件中没有指定EXPOSE对外开放的端口,那么通过docker run -P就不会生成随机端口与指定端口的映射关系
具体dockerfile格式如下:
FROM centos:6.9
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
RUN yum install nginx unzip -y
ADD lijianbo /usr/share/nginx/html ADD 将宿主机指定的目录放到临时容器的当前工作目录
VOLUME /usr/share/nginx/html VOLUME将指定的目录进行持久化
EXPOSE 80 22 如果是多个端口需要随机映射,那么在定义多个端口的时候使用空格隔开
CMD [“nginx”,”-g”,”daemon off;”]
–COPY 将宿主机指定的目录拷贝到临时容器的当前工作目录(如果给的是tar包不会自动解压,ADD会自动解压)
–ENTRYPOINT 指定容器启动时运行的命令,注意与CMD命令的区别,ENTRYPOINT命令是一旦命令指定,后续启动容器时,命令是不能被替换的(启动容器的时候指定的命令,会被当成参数)
具体dockerfile格式如下:
FROM centos:6.9
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
RUN yum install nginx unzip -y
ADD lijianbo /usr/share/nginx/html ADD 将宿主机指定的目录放到临时容器的当前工作目录
VOLUME /usr/share/nginx/html VOLUME将指定的目录进行持久化
EXPOSE 80 22 如果是多个端口需要随机映射,那么在定义多个端口的时候使用空格隔开
ENTRYPOINT [“nginx”,”-g”,”daemon off;”]
–ENV 代表设置环境变量
dockerfile部署mysql数据库格式如下:
FROM centos:6.9
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN yum install mysql-server -y
RUN service mysqld start
ADD init.sh /init.sh
ENV MYSQL_ROOT=123456 # 在dockerfile里也指定一个环境变量,如果在生成的容器中传了环境变量参数,就以传的环境变量为主,如果没传,就以dockerfile中此时指定的环境变量参数为主
CMD [“/bin/bash”,”/init.sh”]
其中dockerfile文件中的init.sh脚本的格式为:
1 | !/bin/bash |
注意:需要测试时,需要安装mysql客户端,命令:yum install mariadb -y
然后生成docker镜像,如:docker build –network=host -t mysql:v1 .
此时,通过该mysql:v1镜像生成容器时,需要加一个参数:–env(这里–env可以简写成-e) “MYSQL_ROOT=56789”,例如:
docker run -d -p 3306:3306 –env “MYSQL_ROOT=56789” mysql:v1
docker镜像的分层
dockerfile构建失败也会产生镜像,无名字
镜像分层的好处:复用,节省磁盘空间,同时相同的内容只需加载一份到内存。
dockerfile优化:
1、尽可能选择体积小linux,alpine
2、尽可能合并RUN指令,清理无用的文件(yum缓存,源码包)
3、修改dockerfile,把变化的内容尽可能放在dockerfile结尾
4、使用.dockerignore(当docker客户端将dockerfile发送到docker server时,会把dockerfile所在的目录的所有文件发送到docker服务端,这样势必会加大通过dockerfile生成的镜像的时间,所以可以编辑.dockerignore文件,将不需要发送给docker server的文件名写在该文件中),减少不必要的文件添加 ./html
容器间的互联(–link是单方向的!!!)
例如:docker run -d -p 80:80 nginx
docker run -it –link quirky_brown:web01(链接的容器名:容器的别名) qstack/centos /bin/bash
ping web01
容器跟容器之间互联,docker就会自动帮你做一个host解析,注意这个–link是单方向的,只有先把需要链接的容器起起来以后,再使用–link链接容器
1 | 循环导入容器镜像的命令:for n in `ls *.tar.gz`;do docker load -i $n;done |
1 | docker容器之间互联部署zabbix服务,具体部署如下: |
docker registry (docker私有仓库)
docker私有仓库的优点:节省带宽,速度快,用户体验好,大规模部署docker的时候应该有一个私有仓库
docker私有仓库是个服务,docker已经为我们提供了部署docker私有仓库的镜像,我们只需启动运行容器就OK 了
例如:
1 | docker run -d -p 5000:5000 --restart=always --name registry -v /opt/myreqistry:/var/lib/registry registry:latest |
上传镜像到私有仓库:
a:给镜像打标签
docker tag centos6-sshd:v3 10.0.0.20:5000/centos6-sshd:v3
b:上传镜像
docker push 10.0.0.20:5000/centos6-sshd:v3
1 | 注意:如果遇到如下报错: |
此时,上面的私有仓库是不加验证机制的私有仓库,谁都可以往上面上传镜像。
1 | 查看镜像列表:http://10.0.0.20:5000/v2/_catalog |
如果,想往docker官方仓库(docker.io)传镜像,需要先进行登录:使用docker login命令
带basic认证的私有仓库registry
basic需要一个basic的账号密码文件,需要借助一个工具httpd-tools,
所以先安装这个工具:yum install httpd-tools -y
mkdir /opt/registry-var/auth/ -p # -p是递归创建目录
htpasswd -Bbn lijianbo 123456 >> /opt/registry-var/auth/htpasswd
然后生成带basic认证的私有仓库容器:
docker run -d -p 5000:5000 –restart=always -v /opt/registry-var/auth/:/auth/ -v /opt/myregistry:/var/lib/registry -e
“REGISTRY_AUTH=htpasswd” -e “REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm” -e
“REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd” registry
如果需要上传镜像,需要先进行登录私有仓库:docker login 10.0.0.20:5000(私有仓库的地址)
注意:带basic认证的私有仓库有个不好的地方,就是上传镜像push和下载镜像pull都需要进行登录验证,所以在企业中推荐使用企业级的私有仓库harbor(它可以做到上传需要登录,下载不需要进行登录)
私有仓库删除镜像比较麻烦,没有命令进行删除,
1)进入docker registry的容器中
docker exec -it registry /bin/sh
\2) 删除repo
rm -fr /var/lib/registry/docker/registry/v2/repositories/nginx
\3) 清除掉blob
registry garbage-collect(垃圾回收) /etc/docker/registry/config.yml
docker-compose(单机版的容器编排工具)
通过docker-compose编排工具一次性可以启动多个容器,它需要编写yml文件
该工具的安装命令:yum install docker-compose -y (需要epel源)
下面是通过docker-compose编排工具通过管理多个容器部署wordpress服务:
mkdir my_wordpress
cd my_wordpress
vim docker-compose.yml
1 | version: '3' #声明了docker-compose的版本,docker-compose有好多版本,其中每种版本的语法都不一样 |
在建好的docker-compose.yml文件中启动的命令为:docker-compose -f docker-compose.yml -d ,参数-d是后台启动,不加,就在前台启动。
注意:由于某种原因使得通过docker-compose启动的某个容器死掉了,你想再启动它,可以通过:docker-compose start 你要启动的容器名
重启docker服务,容器全部退出的解决方法
方法一:docker run –restart=always # 推荐使用
方法二:“live-restore”:true # 不推荐使用
修改docker服务的配置文件/etc/docker/daemon.json
{
“live-restore”:true
}
docker网络类型
docker网络类型主要有四种:None、Container、Host、Bridge
None:不为容器配置任何网络功能,–network=none
Container:与另一个运行中的容器共享Network Namespace,–net=container:containerID(K8S)
Host: 与宿主机共享Network Namespace,–network=host 性能最高,容器跟宿主机端口,先到先得
Bridge: Docker设计的NAT网络模型, 天天用的基本都是Bridge类型
docker跨宿主机容器之间的通信macvlan
macvlan:在默认情况下,一块物理网卡,只有一个物理mac地址,如果我给你虚拟出来多个mac地址,那是不是就可以理解为有多块儿物理网卡,macvlan性能很高的。
macvlan非常类似kvm里面的桥接网络,跟宿主机处于同一网段
创建macvlan网络的命令:
docker network create –driver macvlan –subnet 10.0.0.0/24 –gateway 10.0.0.254 -o parent=eth0 macvlan_1
–driver macvlan :用于指定创建什么类型的网络,此处创建macvlan的网络
–subnet:创建的网络范围,10.0.0.0/24网段
–gateway:指定创建网络的网关地址
-o parent=eth0 :基于那块儿网卡做桥接,此处基于eth0网卡做桥接
macvlan_1:创建的网络名字叫什么,此处叫macvlan_1
在两台宿主机上创建macvlan网络后,如果在其中一台启动宿主机上启动容器,记得不要自动分配IP,自己指定IP最好,例如:
docker run -it –network macvlan_1 –ip 10.0.0.7 –hostname web01 lijianbo:latest /bin/bash
注意:centos创建macvlan网络,网卡不需要设置混杂模式
ubuntu创建macvlan网络,网卡需要设置混杂模式,不然docker之间跨宿主机通信不了。
设置eth0的网卡为混杂模式的命令为:ip link set eth0 promisc on
day05 k8s集群安装
k8s介绍:
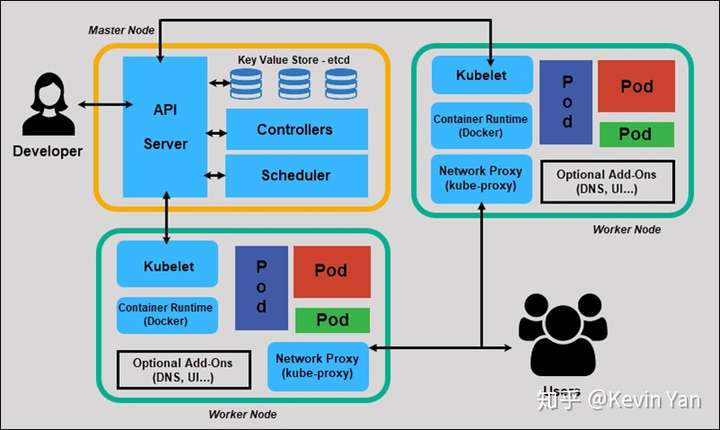
k8s架构:k8s里面分为两种角色,一种是Kubernetes Master(管理节点),一种是Kubernetes Node(随从节点,也称为奴隶节点),这些奴隶节点都受Master控制,每个奴隶节点都要安装Kubelet服务,这样它才能被控制。
Kubernetes Master节点上主要有四个服务:
1、etcd:数据库,它是NoSQL数据库,etcd是key:value类型的存储,它就是k8s的数据库
2、Scheduler:调度器,比如k8s下面有很多节点,如果要起一个容器,具体在哪个节点上创建容器就是由调度器来进行控制,看这些node节点的使用情况,谁的活最少,谁的剩余资源最多,那么就把这个容器安排给谁进行创建。
3、Controller Manager:k8s的巡检机制,它会扫描所有node节点上容器的运行状态,状态不对了,或者死了,立马再给它起一个,如果在一个节点上起不来,那就给它迁移到其他节点给它起起来,始终保证节点上容器的额高可用。
4、API Server:k8s的核心组件,比如通过API Server创建个资源,那么API Server就会把它写到数据库里etcd,这样你下次重启数据还在
我们操作k8s的时候,并不能命令kubelet干啥干啥,我们只能通过命令来控制k8s核心组件API Server
Kubernetes Node节点上主要有两个角色:
1、Kubelet:Kubelet的作用就是接受API Server的调用,来帮助我们创建容器,Kubelet自己创建不了容器,通过调用docker来创建容器,kubelet是通过调用docker来实现对容器生命周期的管理。新版的Kubelet已经集成了cAdvisor,cAdvisor的作用是做容器的监控,最终所有的容器都是运行在node节点上,网站用户访问的并不是Master节点,而是node节点,通过端口映射的方式访问容器内的服务
现在是大规模的使用容器,会涉及跨宿主机的容器之间的通信,所以会涉及一些网络插件Plugin Network(例如:Flannel,Weavenet等),我们安装的时候会使用Flannel
K8S除了一些核心组件外,还有一些附加组件:
1、kube-dns:负责为整个集群提供DNS服务
2、Ingress Controller:为服务提供外网入口,7层负载均衡
3、Heapster:提供资源监控,它使用cAdvisor来实现监控,监控主要是为后面的弹性伸缩做准备的
4、Dashboard:提供GUI友好的web界面
5、Federation:提供跨可用区的集群,把多个k8s集群变成一个,合起来使用
6、Fluentd-elasticsearch:提供集群日志采集、存储于查询,日志收集方案,EFK。
ELK(elasticsearch logstach kibana):
EFK(elasticsearch Fluentd kibana):
收集日志的方式不同,存储都是存储在elasticsearch,展示都用kibana
k8s安装环境搭建:
10.0.0.11 k8s-master
10.0.0.12 k8s-node-1
10.0.0.13 k8s-node-2
三台宿主机都需要进行hosts解析
1、master节点的安装etcd
1、yum install etcd -y
2、vim /etc/etcd/etcd.conf ,修改成下面内容
6行:ETCD_LISTEN_CLIENT_URLS=”http://0.0.0.0:2379"
21行:ETCD_ADVERTISE_CLIENT_URLS=”http://10.0.0.11:2379"
3、systemctl enable etcd.service
systemctl start etcd.service
4、etcd是key:value类型的数据库,我们测试一下设置数据,再获取数据,看看etcd的运行是否正常,有人就把etcd作为消息队列来使用
etcdctl set testdir/testkey0 0
etcdctl get testdir/testkey0
5、etcdctl -C http://10.0.0.11:2379 cluster-health # 检测集群健康状态的命令
注意,etcd原生支持做集群
2、master节点安装kubernetes
1、yum install kubernetes-master.x86_64 -y
2、vim /etc/kubernetes/apiserver
8行:KUBE_API_ADDRESS=”–insecure-bind-address=0.0.0.0”
11行:KUBE_API_PORT=”–port =8080”
13行:将Port minions(随从监听端口打开) listen on 的KUBELET_PORT=”–kubelet-port=10250”注释去掉
17行:KUBE_ETCD_SERVERS=”–etcd-servers=http://10.0.0.11:2379"
23行:KUBE_ADMISSION_CONTROL=”–admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota” 管理员的控制组件中删除ServiceAccount
3、k8s管理节点上剩下的两个服务(Scheduler、Controller Manager)共用一个配置文件,修改如下:
vim /etc/kubernetes/config
22行:KUBE_MASTER=”–master=http://10.0.0.11:8080"
4、启动服务
systemctl enable kube-apiserver.service
systemctl restart kube-apiserver.service
systemctl enable kube-controller-manager.service
systemctl restart kube-controller-manager.service
systemctl enable kube-scheduler.service
systemctl restart kube-scheduler.service
注意,k8s启动的时候一定要先启动kube-apiserver服务
检测k8smaster节点服务起起来的状态的命令是:kubectl get comporentstatus ,如果你看到的全部是健康状态,说明服务正常启动了。
3、node节点安装kubernetes
1、yum install kubernetes-node.x86_64 -y
2、用来在node节点上配置kube-proxy组件
vim /etc/kubernetes/config
22行:KUBE_MASTER=”–master=http://10.0.0.11:8080"
3、vim /etc/kubernetes/kubelet
5行:KUBELET_ADDRESS=”–address=0.0.0.0”
8行:KUBELET_PORT=”–port=10250”
11行:KUBELET_HOSTNAME=”–hostname-override=10.0.0.12”
14行:KUBELET_API_SERVER=”–api-servers=http://10.0.0.11:8080"
4、启动node节点服务
systemctl enable kubelet.service
systemctl start kubelet.service
systemctl enable kube-proxy.service
systemctl start kube-proxy.service
注意,当我们启动node节点的kubelet服务的时候,会自动拉起docker服务的启动,因为它随时要接受master节点的调用
可以在master检测一下,看看node节点服务能否正常链接,使用的检测命令:kubectl get nodes
4、跨宿主机容器间的通信,即所有节点都配置flannel网络
flannel跟k8s配合的好处就是,flannel也需要etcd,我们已经安装etcd了,所以他们可以共用一个etcd
注意,flannel是所有节点都需要安装的
1、yum install flannel -y
2、修改flannel的配置文件
vim /etc/sysconfig/flanneld
FLANNEL_ETCD_ENDPOINTS=”http://10.0.0.11:2379" # 配置flannel连接etcd的一个地址
FLANNEL_ETCD_PREFIX=”/atomic.io/network” # 在etcd里面创建一个key,那么会在这个key的目录下面产生很多网段文件,每产生一个网段就会在这个目录下面产生一个key,这是一个目录,以/atomic.io/network为前缀
其实上面的操作可以通过一条命令在所有节点上执行,命令为:
sed -i ‘s#http://127.0.0.1:2379#http://10.0.0.11:2379#g' /etc/sysconfig/flanneld
3、在etcd上面创建一个key
在master节点上执行下面命令:
etcdctl mk /atomic.io/network/config ‘{“network”:”172.18.0.0/16”}’ #注意后面设置的网段不能跟docker网段进行冲突,一旦冲突就不能正常使用了,定义了flannel网段的范围
yum install docker -y # 安装docker目的是为了后期进行部署k8s的私有仓库
systemctl enable flanneld.service
systemctl restart flanneld.service
service docker restart
systemctl restart kube-apiserver.service
systemctl restart kube-controller-manager.service
systemctl restart kube-scheduler.service
在node节点执行下面命令:
systemctl enable flanneld.service
systemctl restart flanneld.service
service docker restart
systemctl restart kubelet.service
systemctl restart kube-proxy.service
当所有节点都起动后,会在每个节点(master及node)新起一个网段172.18.0.0的IP地址,还有flannel起来以后会影响我们的docker网络,例如:master节点docker网络会由原来的172.17.0.1改为172.18.32.1,所以每个网段可以起254个容器
注意,在各个节点上起容器,直接ping是ping不通的,都丢包了,这是因为docker1.13版调整了我们的iptables的规则,是不允许进行转发的,查看的命令:iptables -L -n ,里面查看Chain FORWARD (policy DROP),默认drop是拒绝的,所以需要我们修改默认的策略,修改的命令为:iptables -P FORWARD ACCEPT,记住所有的节点都要改。注意,这个iptables规则是临时生效的,系统一重启又恢复默认值,所以有一种更为简便的方法,修改docker的systemd的配置,vim /usr/lib/systemd/system/docker.service,在这里面新加一条
ExecStartPost=/usr/sbin/iptables -P FORWARD ACCEPT
在master主节点上配置镜像私有仓库
由于我们的docker版本使用的是docker1.13版,所以他的启用的docker镜像加速以及信任的私有仓库的方法跟以前不一样
1 | 所有节点修改 |
什么是k8s,k8s有什么功能?
k8s是一个docker集群管理工具
k8s的核心功能
自愈:重新启动失败的容器,在节点不可用时,替换和重新调度节点上的容器,对用户丁一的健康检查不响应的容器会被中止,并且在容器准备好服务之前不会把其向客户端广播。
弹性伸缩:通过监控容器的CPU的负载值,如果这个平均高于80%,增加容器的数量,如果这个平均低于10%,减少容器的数量
阿里云上面也有弹性伸缩服务是ECS服务,在阿里云的弹性伸缩之前有个负载均衡服务叫做SLB
服务的自动发现和负载均衡:不需要修改您的应用程序来使用不熟悉的服务发现机制,Kubernetes为容器提供了自己的IP地址和一组容器的单个DNS名称,并可以在他们之间进行负载均衡。
滚动升级和一键回滚:Kubernetes逐渐部署对应用程序或其配置的更改,同时监视应用程序运行状况,以确保它不会同时终止所有实 例。如果出现问题,kubernetes会为您恢复更改,利用日益增长的部署解决方案的生态系统。
k8s的发展史
2014年docker容器编排项目立项
2015年7月 发布kubernetes 1.0,加入cncf(cloud native compute foundation云原生计算基金会)基金会
2016年,kubernetes干掉两个对手,docker swarm, mesos
2017年
2018年 k8s从cncf基金会首个毕业的项目
2019年:发布1.13,1.14, 1.15
谷歌有15年容器使用经验,最早使用borg容器管理平台,谷歌曾用golang重构了borg,最终转向kubernetes。
k8s的安装
yum安装 1.5版 最容易安装成功,同时是最适合学习的
源码编译安装—难度最大 可以安装最新版
二进制安装—步骤繁琐 可以安装最新版 shell,ansible,saltstack
kubeadm 由谷歌推出,安装最容易,但是基于谷歌,网络层级跨越不过去,可以安装最新版
minikube 用于开发k8s开发环境,适合开发人员体验
k8s的应用场景
K8S最适合跑微服务项目!
微服务:是一种软件设计架构(开发的架构),在微服务出现之前,开发使用的都是MVC架构(一个功能一个目录),而微服务可以理解为拆业务,一个功能就是一个集群
微服务的优点:
1、能承受更大的访问压力;
2、服务的健壮性更好;
3、降低代码的复杂度,代码的编译时间也会减少;
day06 k8s资源
1、pod是K8S最小的资源单位。k8s的所有资源都可以用yaml文件来创建,yaml的文件是强调缩进的语法,用缩进来显示它的层级关系
k8s yaml的主要组成(4大块):
1 | apiversion: v1 api版本 |
例如:k8s_pod.yaml
1 | apiVersion: v1 |
pod资源:至少要由两个容器组成,pod基础容器和业务容器组成
通过yaml创建资源的命令为:kubectl create -f k8s_pod.yaml
查看已经创建的k8s的pod资源的命令为:kubectl get pod
查看已经创建的k8s的pod资源调度到哪个节点的命令:kubectl get pod -o wide
查看已经创建的k8s的pod资源的具体描述命令:kubectl describe pod nginx(你当时创建pod资源的名字,此处是上面创建pod资源的名字nginx)
注意:但是此时创建的pod资源的状态一直是:ContainerCreating,通过kubectl describe pod nginx查看描述信息,发现出现报:image pull failed for registry.access.redhat.com/rhel7/pod-infrastructure:latest错误,造成这个是缺少红帽的证书:/etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt,这个文件存在,但是个软链接,最终等效于不存在,到网上查找解决方法,
方法一. yum安装
yum install rhsm
方法二 (我是用这方法解决的)
执行命令:
② rpm2cpio python-rhsm-certificates-1.19.10-1.el7_4.x86_64.rpm | cpio -iv –to-stdout ./etc/rhsm/ca/redhat-uep.pem | tee /etc/rhsm/ca/redhat-uep.pem
前两个命令会生成/etc/rhsm/ca/redhat-uep.pem文件.
③ docker pull registry.access.redhat.com/rhel7/pod-infrastructure:latest
都是解决了下载image pull failed for registry.access.redhat.com/rhel7/pod-infrastructure:latest镜像的问题,但都不太好用,我们把它改成从私有仓库下载,此时我们编辑node节点kubelet的配置文件,vim /etc/kubernetes/kubelet,修改里面的基础容器的镜像地址为我们私有仓库的地址,修改为:KUBELET_POD_INFRA_CONTAINER=”–pod-infra-container-image=192.168.1.101:5000/pod-infrastructure:latest”,重启kubectl:systemctl restart kubelet
k8s资源到底是什么?
1、k8s的pod资源为什么至少要启动两个容器呢?
一个底层基础容器pod用于提供k8s各项高级功能,一个业务容器来提供基本的业务部署,这样,可以保证容器的镜像比较轻量化,同时提供负载分担的比较合理。业务容器可以有多个,反正目前我见过的就是(1个pod容器+4个业务容器)
pod是k8s最小的资源单位
pod资源可以保证创建的容器业务运行的高可用
k8s另一个资源(ReplicationController,简称rc)副本控制器资源
rc:保证指定数量的pod始终存活,rc通过标签选择器来关联pod
如果跑着pod资源的某个节点node挂了(比如:node节点死了,物理机坏了),那么对于k8s上这个pod,并不会给它换个节点,如果节点死了,跑在这个节点的pod也就死了,那么rc就解决了这样的问题。
k8s资源的常见操作:
kubectl create -f xxx.yaml
kubectl get pod | rc
kubectl describe pod nginx
kubectl delete pod nginx 或者 kubectl delete -f xxx.yaml
kubectl edit pod nginx
例如:k8s_rc.yaml
1 | apiVersion: v1 |
创建rc资源使用的命令还是:kubectl create -f k8s_rc.yaml 会提示replicationcontroller “nginx” created
rc就具有k8s核心功能自愈及滚动升级和一键回滚的功能。
滚动升级的操作:
再新建一个k8s_rc2.yaml,修改里面的内容如下:
1 | apiVersion: v1 |
我们可以使用命令来查看k8s_rc.yaml和k8s_rc2.yaml的区别,命令为:vimdiff k8s_rc.yaml k8s_rc2.yaml
此时,滚动升级的命令为:kubectl rolling-update nginx(rc的名字) -f k8s_rc2.yaml(指定另一个配置文件) –update-period(指定升级的时间间隔,不加该参数,默认值为1分钟)=2s(此处我们指定的滚动升级的时间间隔为2秒)
rc一键回滚
rc回滚的操作是上面的逆向操作,反过来就可以了,具体命令为:
kubectl rolling-update nginx2 -f k8s_rc.yaml –update-period=10s
rc滚动升级和一键回滚总结
升级:
kubectl rolling-update nginx -f nginx-rc1.15.yaml –update-period=10s
回滚:
kubectl rolling –update nginx2 -f nginx-r.yaml –update-period=1s
k8s另一个资源service资源(简称svc)
service帮助pod暴露端口

我们的service资源就帮你做vip、clustIP、负载均衡,并且帮你做端口映射
下面是一个service的例子:
1 | apiVersion: v1 # api版本 |
我们等会儿会访问宿主机的30000端口映射到vip的80,vip的80端口再负载均衡到容器的80端口

创建svc资源的命令为:kubectl create -f k8s_svc.yaml
svc资源扩展
我们在调整rc里面的副本数目有两种方法:
方法1:kubectl edit rc nginx(创建的rc资源的名字),修改里面replicas的值
方法2:kubectl scale(它用来负责调度副本的数量) rc nginx –replicas=5
进到pod容器里去的命令:kubectl exec -it nginx-jfn63 /bin/bash
注意1:我们在做svc资源的端口映射,宿主机启用的端口(默认)范围只能是30000–32767,其实这个范围是可以改的,改的话需要改我们的配置文件,在master节点改,vim /etc/kubernetes/apiserver,修改里面的参数值KUBE_API_ARGS=”–service-node-port-range=3000-50000”,然后systemctl restart kube-apiserver.service
注意2:我们在做srv里面vip的地址范围,默认是10.254.0.0/16,注意,这个地址跟范围也是可以改的,修改的地方也是在master节点改,vim /etc/kubernetes/apiserver,修改里面的参数值KUBE_SERVICE_ADDRESSES=”–service-cluster-ip-range=10.254.0.0/16”
service默认使用iptables来实现负载均衡,k8s 1.8新版本中推荐使用lvs(四层负载均衡)
k8s的另一个资源deployment资源
注意,rc在滚动升级之后,会造成服务访问中断,于是k8s引入了deployment资源,它也是保证pod容器的高可用。
创建deployment的yaml文件,例如:
1 | apiVersion: extensions/v1beta1 |
rs是rc的升级版,rs不会自动创建,它会随着deploy资源的创建自动生成
注意,deploy升级比我们的rc升级要简单的多,使用命令:kubectl edit deployment nginx-deployment 修改里面的镜像版本就可以了
k8s的deployment资源的回滚
方法1:第一种回滚方法跟deployment升级相似,也是使用命令:kubectl edit deployment nginx-deployment 修改里面的镜像版本就可以了,但不推荐这样使用,它有专门的命令支持资源回滚。
方法2:kubectl rollout history deployment nginx-deployment(资源类型) ,通过这个命令可以查看deployment的历史记录版本有几个,回滚的方法是:kubectl rollout undo deployment nginx-deployment 不加参数是回滚到上一个版本,如果想回滚到指定的版本可以加参数:–to-revision ,例如:kubectl rollout undo deployment nginx-deployment –to-revision=1 回滚到指定的第一个版本

我们发现,在查看deployment的历史记录版本有几个的时候,里面的CHANGE-CAUSE为none,如果想让里面记录内容,就需要引入一种新的方式来创建资源了,使用命令行来创建deployment资源:
kubectl run nginx –image=192.168.1.101:5000/nginx:1.13 –replicas=3 –record
通过命令行来对刚才创建的deployment资源进行升级,可以使用命令:
kubectl set image deploy(资源类型) nginx(资源的名字) nginx(容器的名字)=192.168.1.101:5000/nginx:1.15
1 | 总结: |
tomcat+mysql练习
在k8s中容器之间相互访问,通过vip地址
我们所创建的所有资源都保存在etcd里,如果把etcd的数据清空,就是对k8s进行资源还原,初始化,我们可以通过etcd的配置文件/etc/etcd/etcd.conf里了解到etcd的数据存放目录为:/var/lib/etcd/default.etcd
那么清空资源的操作为:
1 | master节点的操作: |
1 | node节点的操作: |
注意,查看vim /etc/sysconfig/flanneld网络,它也用到了etcd,所以当我们重启flanneld服务发现连不上,注意联想flannel网络的安装,注意要在主节点上设置key来确定我们flannel网段的范围

所以,最终master节点和node节点执行的命令为:
1 | master节点的操作: |
注意:这两个服务先起动数据库,然后再启动tomcat的web服务
下面是mysql_rc.yaml的配置文件:
1 | apiVersion: v1 |
下面是mysql_svc.yaml的配置文件:
1 | apiVersion: v1 |
下面是tomcat_rc.yaml的配置文件:
1 | apiVersion: v1 |
下面是tomcat_svc.yaml的配置文件:
1 | apiVersion: v1 |
k8s练习:实现在k8s中使用rc运行wordpress+mysql.
下面是mysql_rc.yaml的配置文件:
注意,这里面的前提是mysql:5.7镜像已经上传到node节点(192.168.1.102),且该镜像也通过docker tag 更改了标签名 :192.168.1.101:5000/mysql:5.7
1 | apiVersion: v1 |
下面是mysql_svc.yaml的配置文件:
1 | apiVersion: v1 |
注意,我们在写yaml文件的时候是有资料可查的,可以查看yaml的具体语法,这个查询的具体命令是kubect explain(解释) pod.spec ,这个是查询pod资源下的spec属性有哪些选项的具体用法
下面是wordpress_rc.yaml的配置文件:
注意,这里面的前提是mysql:5.7镜像已经上传到node节点(192.168.1.102),且该镜像也通过docker tag 更改了标签名 :ge: 192.168.1.101:5000/wordpress:latest
1 | apiVersion: v1 |
下面是wordpress_svc.yaml的配置文件:
1 | apiVersion: v1 |
day07 k8s的扩展服务、核心功能及其持久化
我们之前使用的容器之间互访使用的是VIP(即clusterIP),那么它其实也可用主机名(其实是svc的名字),如果要使用svc进行通信,那么它就需要依赖一个附加组件服务,这个附加组件的服务叫做dns服务
K8S除了一些核心组件外,还有一些附加组件:
1、kube-dns:负责为整个集群提供DNS服务,它的作用是把我们的svc名字解析成相应的vip地址
2、Ingress Controller:为服务提供外网入口,7层负载均衡
3、Heapster:提供资源监控,它使用cAdvisor来实现监控,监控主要是为后面的弹性伸缩做准备的
4、Dashboard:提供GUI友好的web界面
5、Federation:提供跨可用区的集群,把多个k8s集群变成一个,合起来使用
6、Fluentd-elasticsearch:提供集群日志采集、存储于查询,日志收集方案,EFK。
如果想一批一批的删除资源,可以使用命令:kubectl delete -f .
如果想快速创建资源,可以使用命令:kubectl create -f .
注意,执行这两个命令的前提是,必须在当前目录.下有yaml文件的存在。
通过上面的两条命令一折腾,svc的vip地址就会发生变化,从而导致,我们创建的业务链接失败,比如:wp-mysql的svc地址发生了改变,从而导致wordpress连接wp-mysql数据库失败。
至此,我们引入DNS服务,从而把svc的名字解析成vip的地址,dns服务也不需要安装,k8s除了基础架构是使用二进制,其他的都使用容器
k8s的dashboard管理平台部署
1、下载dashboard镜像,并修改它的标签:
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kubernetes-dashboard-amd64:v1.10.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kubernetes-dashboard-amd64:v1.10.0 192.168.1.101:5000/kubernetes-dashboard-amd64:v1.10.0
2、编辑dashboard_rc.yaml和dashboard_svc.yaml配置文件
下面是dashboard_rc.yaml的配置:
1 | apiVersion: extensions/v1beta1 |
下面是dashboard_svc.yaml的配置:
1 | apiVersion: v1 |
点击上方按钮,请我喝杯咖啡!
扫描二维码,分享此文章